April 15, 2024
Link: Validating the Unit Correctness of Spreadsheet Programs
Validating the Unit Correctness of Spreadsheet Programs via Lambda the Ultimate
June 13, 2003
Grids and Subgrids
I've been thinking a while about Lists actually being represented as
Grids which are magically embedded into the top-level Grid.
After waffling about it in the last 2 entries I'm ever more convinced
that this is the way to go.
This is potentially much more complex than I'd planned, but it makes some
things simpler. Some notes:
- Though the data will be stored in the sublist, in the display
the cells will be contiguous to the main grid (and in fact could
be selected by the main grid too). e.g. B5 could be
Sales[1] (e.g. row 1 in column Sales).
- For convenience, the UI will show list headers instead of A B C D etc.
if you are in the middle of a list.
(In Excel you have to explicitly request this behaviour with
Split Window and Freeze Panes).
- If you tried to copy a cell from a List containing a
reference to a column (=Sales_Result*2) to outside the list,
e.g. where this column doesn't exist, the cell should set itself as an
error.
- (On the other hand, the main columns A B C D etc. should be referrable
within the sublists too).
- Sorting a sublist will be easy because you can just order the rows
in the grid.
Otherwise you'd have to buffer and copy cells around which would be
a pain.
(Or only sort by whole-row, which is admittedly very common: for example
Excel still reverts to whole-row sorting under some circumstances, like when
you share a worksheet!)
- Curses: MIDP doesn't appear to have a sort method on Vectors!
Time to look at those algorithm books again...
Spreadsheets and $Horrible$Syntax
Yuk I hate this spreadsheet syntax:
$A$1:$F$100
I've always hated it, and I don't want
to have to use it in Gilgamesh. On the other hand it's clear why
it's needed:
the kind of formula I described in the last entry.
When copying or filling cells,
you want some of them to offset their references and some of them not to.
By placing the dollar ($) sign before any reference that doesn't change,
you have fine grained control over how this is done.
My thoughts on this are as follows.
-
Gilgamesh will be a light-weight spreadsheet designed for small
devices. I don't want to sacrifice power if I don't have to,
but if I can get simplicity and useability by sacrificing it then
so be it.
-
If I've referred to a cell in the same row, then it's likely
that I'll want the reference to offset downwards.
Whereas if I've references a cell in another row then it's
likely to be a constant value. So I can use the heuristic:
- Offset any references that are in the row.
- Keep references outside the row fixed.
-
On the other hand, if I've referred to a constant value,
then I would probably have been better off giving it a name.
=150*A5 tells me nothing about the formula, whereas
=150*GBP_to_EUR gives me a named reference (which
won't be offset) and tells me that I'm converting 150 pounds Stirling
into Euros.
- Offset any direct references
- Keep references to names fixed.
-
I don't think I've ever seen any reason to offset an
entire range. This behaviour causes me nothing by
irritating bugs like the above.
- Consider only ever offsetting single-cell references.
- This is open to reasoning: if your spreadsheet usage is different to
mine and you find this useful, let me know.
-
With the concept of row-scoped names, we could insist that
no offsetting is ever done!
- References to cells on same row actually only maintain a reference
to the corresponding column. The actual cell referred to is
dynamically calculated.
- References to actual cells are never offset.
- A1: =B+B1 would be equivalent to =B1*2, however if
filled down (or moved) A2: =B+B1 dynamically becomes =B2+B1.
- I originally thought that this would have an impact on the evaluation
ordering (Previously described in detail).
But in fact it should be minimal.
When the formula is calculated it will return references to the actual
cells (B1, B2) involved. However, internally it will only store the
reference to the column. This means that every time the Orderer notices
a change it will deal with registering and deregistering the Cell from the
evaluation tree as appropriate.
The only additional complexity is that the formula becomes slightly
range-volatile. That is, it is affected by movements of the cell
between lines, but not by insertions/deletions in the Grid that happen
to change the line's address. This could easily be represented by an
additional special node in the evaluation graph.
I hope that it's clear that there isn't a Right Way to do things. But I
think that there may be a better way than the current standard
semantics, where better in this case means
"more optimized for the simplest possible task that someone would want to
do on a constrained device like the SE P800".
NB: we will probably offer an OFFSET() formula just like Excel. But it'd
be nice to have to use it for just the complex stuff, and make the easy
stuff easier!
Excel's dynamic named ranges considered harmful.
Though I'm stuck in nitty-gritty implementation work, and this isn't a priority
for some time yet, I thought I'd whine for a moment about Microsoft Excel's
dynamic ranges.
Lists
I usually use Excel for managing lists. Lists have a header row with the
title of the column ("Name", "Country", "Score") and any number of rows
underneath them. You will often want to write formulas that act on a whole
column: for example
- SUM: add up the figures in a column
- VLOOKUP: look up a value in one column and return its
corresponding value. (For example Name -> Address lookup)
That's great if you already know how many rows there are going to be.
Otherwise you can either
- Insert a new row in the middle of the range. (Because the range runs
from the first row object to the last row object this just
works.)
- Start inputting the data on the next row after the last row in the list.
This, on the other hand, won't work. The range that you referred to in the
formula doesn't change. So you're going to have to dig up any formulas
that need to be changed and modify them by hand.
You could make your range into a whole column (=SUM(A:A)) but
this could be wasteful (though I don't doubt that Excel optimizes this
case and doesn't scan thousands of empty cells unnecessarily) and is also
unsubtle (if you have any cells below or above the list, they'll be included
too - including the Header row itself!)
Dynamic Named Ranges
Excel's answer to this is Dynamic Named Ranges.
From the useful
OzGrid
page on the subject:
Possibly one of Excels most underutilized aspects is its ability to create
dynamic named ranges that will expand and contract according to the data in
them.
Let's see how you create a named range.
Go to: Insert>Name>Define and in the Names in workbook box type any one
word name (I will use MyRange) the only part that will change is the formula we
place in the Refers to box.
OK so far, note that you can't just access a dynamic range from the formula
bar, they have to be named (hence "dynamic named range")...
Now let's see an example of a formula defining a dynamic range:
1: Expand Down as Many Rows as There are Numeric Entries.
In the Refers to box type: =OFFSET($A$1,0,0,COUNT($A:$A),1)
And at this point you might already understand why this functionality is
"underrated" ;->
The OFFSET() function takes these arguments
- the initial range ($A$1)
- the head row offset (0 - the row remains 1)
- the head column offset (0 - the column remains A)
- the tail row offset (COUNT($A:$A) - count the number of non-blank cells in
column A and offset the end of the range by that number)
- the tail column offset (1 - being the width of the new range)
The logic is sound, but the syntax is spuriously ugly for something so simple.
3:Expand Down to The Last Numeric Entry
In the Refers to box type: =OFFSET($A$1,0,0,MATCH(1E+306,$A:$A))
If you expect a number larger than 1E+306 (a one with 306 zeros) then change this to a larger number.
This is quite clever in a horrible-kludge way. MATCH() with these
parameters finds the largest number in an ascending list that is equal to
or less than the parameter. As it's expecting an ascending list, I guess
that it optimizes by starting the search from the end and looking backwards.
Because the first number that will be found is bound to be smaller than
the very large number provided, this hack will work.
I don't want to come across as criticising the OzGrid site or the useful
examples that it provides. Certainly for the advanced searches that it
goes on to describe ("Expand down one row each week", etc.) this syntax is
flexible and powerful. But it's fairly clear from the entries that I
quoted that a main use is to sum or manipulate columns in a list.
And this really should be simpler! Indirection like used in OFFSET, coupled
with bizarre hacks to locate the endpoints is liable to be tricky to use,
debug, and maintain, and cause subtle errors.
A new hope
I'm thinking along these lines for Gilgamesh:
- Every list will have dynamic named ranges created automatically for
each column.
- These ranges will usually be named after the header row. For example a
Column header which has "Q4 Sales" might generate a dynamic range called
"Q4_Sales".
- An external formula can now simply do =sum(Q4_Sales).
- Of course if someone had already registered a range called Q4_Sales
we'll have to do something appropriate mumble mumble handwave handwave ;->
- If we change the header text to "Q4 Sales figures", the range will rename
itself to "Q4_Sales_figures", and because all referencing formulae are
pointing at an object, not a String, they will magically have rewritten
themselves (=sum(Q4_Sales_Figures)).
Single cell ranges
And something that might be more controversial: single cell dynamic named
ranges.
- Within a list, you are more likely to refer to a cell within your row
than to a whole column. For example, consider the columns
- First Name
- Last Name
- Full Name
You'd like Full Name to be automatically generated.
I think a formula like
Full_Name: =First_Name+" "+Last_Name
is about as clear as you can get, and certainly clearer than the kind of thing
I write in Excel (=A5+" "+B5).
So, within a row in a list, names will be scoped by default to the row itself.
-
Of course you might want to be able to refer to a whole column, for example
to compare a score with all the competitors (=(Score - AVERAGE(Score))/100)
But this won't work: how can we tell that the first 'Score' is a range value
but the second is a single value?
I think it would make sense for a column in a list to take on the semantics
of a column in a grid. So how about
(Score - AVERAGE(Score:Score))/100)? The construct :
is parsed as a column range (A:B etc.) so this is relatively
intuitive.
But it's ugly, and it's a lot of typing. Actually, on a pen-based device
like those targeted by Gilgamesh it's a lot of hand-writing recognition ;->
Perhaps we can assume that a column range where one column is omitted
is actually a single column:
(Score - AVERAGE(Score:))/100
I had considered going the Perl way and having an array sigil
(Score - AVERAGE(@Score))/100 which stands out
more. But I like the idea of treating columns of a list just
like columns of a Grid. After all you can sort by them, which
is an extension of this abstraction. It'd be nice to have
consistency.
Consistency
If we want consistency, then I suppose that we should
be able to refer to the Grid columns (A B C D E ...)
within a row.
C1: =A+B (e.g. is the same as =A1+B1)
This could help resolve an error that I often make: when I was
testing the Average example above, I filled in A1:A4 in an
Excel worksheet, and then put in A1:
=(A1 - AVERAGE(A1:A4))/100 which gave the right result.
But when I filled down, I forgot as I so often do that this
doesn't just move A1...
- =(A2 - AVERAGE(A2:A5))/100
- =(A3 - AVERAGE(A3:A6))/100
- ...
I don't want A1:A4 to change... should have put A$1:A$4. Which leads me
to my next rant.
UPDATE (2003-06-19):
From
this page, I found this tip
[Ctrl][Shift][F3]: Automatically creates Named Ranges from the headers for the selected table of data with row or column headers.
This seems to do something similar to what I want, but has some oddities, which
I will play with
May 28, 2003
Modeling grid Ranges
I've discussed model objects like
- Cell
- Column
- Row
- Range
but I've been a little vague about Ranges, mainly because I had only
the vaguest idea about how they were going to modeled.
I initially thought
that as a Range could either be
- A 'square' range bounded by a Cell at the top-right corner, and another
cell at the bottom-left corner
- A 'Line' range bounded by a Line (Row or Column) and another Line.
that a Range would have a head and a tail property that
would contain either a Cell or a Line. The various complexities of
inheritance and interfaces managed to get me completely confused for some
time, until I finally worked out that the idea of storing Cells
as the end-points of a square range is wrong.
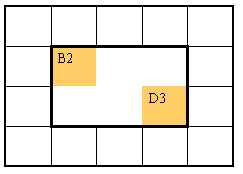 What we should do instead is store the start-row and -column, and end-row
and -column.
What we should do instead is store the start-row and -column, and end-row
and -column.
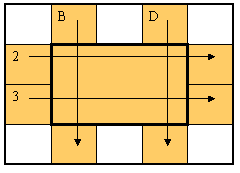 Admittedly, the difference may seems slight (especially as a cell largely
consists of a row and a column reference anyway), but this scheme gives
at least two advantages:
Admittedly, the difference may seems slight (especially as a cell largely
consists of a row and a column reference anyway), but this scheme gives
at least two advantages:
-
The cell at the endpoint is no longer significant.
We can delete that one cell without having to play around with
the boundaries of the range. (Admittedly, this does have its
conceptual disadvantages too). It's only when the row or column
itself is deleted that we have to do some hard work.
-
More importantly, it is now very easy to model all the different
kinds of ranges in the same scheme:
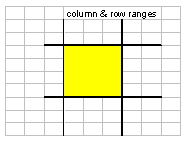
- 'Square' range (A1:E5)
- Simply defined by the start-row and -column, and the end-row and -column.
- Row range (1:5)
- Contains a start-row and end-row. start- and end- column however are
undefined (null,)
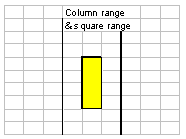
- Column range (A:C)
- Contains a start-column and end-column. start- and end- row however are
undefined (null,)
- Cell (A1)
- Start- and end-column are the same (the column that the cell is in),
as are start- and end-row.
- Single column (A)
- A column range whose start- and end- column are the same.
- Single row (A)
- A row range whose start- and end- row are the same.
- The entire grid(A)
- A row range whose row and column bounds are all undefined.
I've mentioned intersection before: here are some examples:

 The algorithm is quite easy:
The algorithm is quite easy:
- Take two ranges, R1 and R2
which each have
rowhead,
rowtail,
colhead,
and coltail.
We want to get the intersection R3:
- Starting with Rows:
- Take R1's head and compare to
R2's head.
Return the maximum (that is, the one with the highest
position)
(e.g. R3.rowHead = max(R1.rowHead, R2.rowHead))
If either of the values is null, then return
the other value.
(If both are null, then return null)
- Take R1's tail and compare to
R2's tail.
Return the minimum (that is, the one with the lowest
position)
(e.g. R3.rowHead = min(R1.rowTail, R2.rowTail))
If either of the values is null, then return
the other value.
(If both are null, then return null)
- If the Tail is lower than the Head, (if R3.rowTail <
R3.rowHead) then there was no intersection.
Break at this point, returning null!
- Now do the same with columns.
-
R3 is now a fully fledged Range objects with
head and tail row and column values.
To tell if one cell contains each other is very easy - it is the
case when the intersection is exactly the same as the contained
cell:
if (R1.intersect(R2) == R2) return true
(The Range implementation in Java is going to include some rather
lovely examples of .equals, .hashcode, .compareTo
to make the API nice to read and use.)
For various reasons, it will sometimes be useful to know if a
Range is a Line (Row or Column) range. This can be worked out
quite easily when needed (they are the ones that have null
values on one axis!), or it could be cached as a boolean property.
Cells
But Cells are a different matter.
To contrast them to Ranges:
- Ranges are stored directly in the Grid in a list (Vector?).
Cells are stored in the Lines that they belong to.
- Cells are evaluable: they can be passed to the Evaluation Engine
to be re-calculated. They also contain a Formula, a Value, and
other data like the Parse-Tree for the formula.
(Michael tried to remind me that Ranges could also have formulae - Excel
calls them array formulas - but I'm sticking my head in the sand about
that for now!)
My current thinking is that Cell should be a distinct subclass of
Range. If the Range class is ever asked to create a single-cell
Range (for example, through an intersection), then it should instead
return a Cell object. (I think that in Java this would be done by having
all creations of Range objects through a factory method which will return
a Cell subclass object instead as appropriate). Effectively this means that
there must be no single-cell Ranges. If a Range becomes single-cell at any
point, then it should turn itself into a Cell instead. (Which means, in
implementation terms, that it should pass on all of its dependencies onto
the relevant Cell object, and then delete itself).
Hmmm, I'm not sure if I should make a distinction between Ranges and Cells.
If I remember rightly, Excel doesn't have a Cell object - its Ranges have
.Cells properties which return an enumeration of each single-cell
range contained in the range. More thinking required.
May 26, 2003
Evaluation order and evaluation engines.
If you are following this thread of how evaluation
order will be calculated (and if you are, please
do let me know!) then you might think "Thank
$deity that's over, maybe now he'll go and
write some code". But though I think that the
evaluation order Evaluation order and evaluation engines.
calculation seems pretty sorted,
I've now come to an interesting point: how do I
build up the dependency list in the first place?
What I mean is, how do we know that
=SUM(A1, A1:B2, Q4_Sales)
contains references to the cell A1, the range
A1:B2, and the alias (and there's
another story) Q4_Sales?
A naïve idea (and it's the one I first thought
of) would be to do a search on the formula for
anything that looks like a cell, range, or alias
name, and add that to the dependency list. But of course
it could find false positives
="A1+B1=" & C1
would put the cells A1 and B1, as well as
the required C1, into the dependency list.
So some knowledge of the syntax of the expression language
is required. Clearly, the Evaluation engine itself knows
its language's syntax, and should be responsible for determining
which nodes its formulae refer to.
Imagine that a cell contains (at least) these attributes
- Value (CellValue object)
- Formula (String)
- FormulaParseTree (ParseTree object)
- Dependencies (an array or Vector of Node objects)
When a cell is passed to the Engine, with a new formula,
the Engine can store its parse-tree in the FormulaParseTree
slot. I'm supposing that ParseTree will be a
tagging interface: this means that the Engine isn't required
to store its parse-tree in any particular way.
The engine will also store the dependencies that it finds.
These must all be nodes: which could be
- Cell object
- Range object
- Alias object ("Q4_Sales")
but also:
- Volatile
- Address
So: some examples
- =A1 + A2 (Cells A1, A2)
- =TIME + 1(Volatile)
- =Q4_Sales * RANDOM(Alias 'Q4_Sales', Volatile)
- =CONCATENATE(ADDRESS(ExampleCell), ": ", ExampleCell) (Alias 'ExampleCell', 'Address'-dependency node.)
Of course, the Engine itself has no responsibility over the evaluation
order! (We want to do it right once. Whichever evaluation engine we plug
in, it should concentrate on evaluating expressions. The evaluation-ordering
class on the other hand will just worry about evaluation order, and leave
syntax etc. to the Engine). So the process could look something like this:
I'm hypothethizing two classes called Order and Engine to
show the split of responsibility.
- User changes formula of cell A1
- Order checks which dependencies A1 already has.
- Order asks Engine to parse the A1.
- Engine parses the formula.
- (NB: Engine will have a reference to the relevant Grid
object, and will request the object reference corresponding to the
names - A1, A1:B5, Q4_Sales etc - from it).
- Engine updates Al's dependencies.
- Order compares the delta between Al's old dependencies
and it's new ones.
- If any dependencies are new, Order registers Al as a
dependent of the appropriate Node.
If any dependencies have gone, Order de-registers Al
from the appropriate Node.
Then... we need to evaluate the changes to A1 itself so:
Order:
- ...creates a new Root node.
- ...creates an edge from Root to Volatile
- (but, as this is just a formula change, doesn't create an edge to
Address.
- ...creates edges from Root to all cells changed
(just A1 in this instance).
- ...scans every Range object and adds an edge from Root
to any that intersect with the changed range (A1).
- Order now does a toposort starting from Root
- Order takes each cell in turn (e.g. in toposorted order)
and passes just the evaluable ones (Cells, not Ranges, Names, Volatile,
or Address) to Engine to evaluate.
- Engine takes the cell's parse-tree, calculates the result,
and stores it in the cell's Value property.
May 25, 2003
Recalculating location-specific formulae
Thanks again to
Michael for some interesting email discussion
which has helped me clarify my thinking about this.
But first, a recap:
Recap
As discussed, Cells will not contain their (x,y)
co-ordinates, only knowledge of which Row and
Column they are in.
Coupled with the fact that after a formula is
parsed, references to cells/ranges are stored
as Object references to the cell or range
in question, certain actions can be done very
efficiently.
- Inserting a row or column
Inserting a row causes the following rows to
renumber themselves. Any references will still
point to the correct objects. The next time
they are edited, the formula in the Edit box
will reference the new name of the cell.
(Compare to a scheme where each cell knows
its own address: in this case, inserting a row
would require cycling through all the subsequent
cells in the grid to tell them to change their address).
- Deleting row or column ranges
After the various tasks required for any
deletion (clobbering any cells and ranges completely
contained in this range; scheduling other ranges which
intersect with this range for update), all we need
to do is remove the rows from the grid, and renumber
subsequent rows.
- Moving a row or column range
Any ranges that are completely contained in the range
being moved will move along with it just like that!
However, with ranges that intersect, we would need to
schedule updates as with deleteion.
(Though I've glossed over a couple of things, like what
happens to a range when you delete part of it...
which is slightly more involved than I've let on, but
I'll talk about this in more detail soon when I discuss
the Range model soon.)
Location specific formulae
In a recent entry, I mentioned that I wasn't planning to
support formulae like
=ADDRESS(A1)
which returns the address (in
one form or another: "A1", or "R1C1", or "Q4_Sales").
Actually, that's not as wildly useful as it could be.
How about
=OFFSET(Oranges, 1, 0)
which returns the contents
of the cell at offset (1,0) from the cell called "Oranges".
Or, maybe
=CELL("A1")
which
returns the cell at address A1.
These formulae (and possibly other, better, examples?) could
all be affected by insertions, deletions etc. of ranges.
Because of this, I was very tempted not to support them...
And then it occurred to me that I'd missed a (very simple)
trick. Add a Node to the update graph called "Address" or
similar, which is equivalent to the "Volatile" node I
mentioned:
Whenever the Evaluation engine notices one of these address-dependent
formulae, it will request for the cell to be added to this node.
The node will automatically get added to the "Root" update node
when the update is any operation that could change a cell's
address. Which brings me to the next entry on how the Evaluation engine will
interface with all of this.
May 23, 2003
In brief - J2ME plugin, spreadsheet FAQ
Via
tomaspascual.net,
news of an
IntelliJ J2ME plugin.
And from Michael Zemljanukha, the
comp.apps.spreadsheets FAQ. Lots more to read [sigh].
Cell updates moves, insertions, deletions: evaluation and semantics,
I think that the dependency graph model is looking pretty good... but
there's a bit more complexity to go...
Let's look at the actual scenarios in which one or more cells are
changed: some of these points are more or less arbitrary - it's
interesting to compare these behaviours to the semantics of existing
spreadsheets.
- Standard Cell modification
Usually one cell modified by inputting into the cell (or into a formula
bar at the top of the screen.)
But we might implement multiple cell update: e.g. by selecting a range
and then inputting. Or by filling down (for example, a series).
In these cases the value may need to be calculated (1, 2, 3, 4, ...)
or a cell offset may be incremented (A1+1, A2+1, A3+1, A4+1, ...).
Note that the modification to a cell could change the dependency graph!
The evaluation engine should parse the new formula, and compare the previous
dependencies with the new.
- =A1*2 --> =A1/200 ... formula has changed, but the
graph hasn't.
- =A1*2 --> =(A1+B1)*2 ... Cell B1 is a new dependency.
Register cell with B1 as a dependant.
- =A1*2 --> "All gone" ... Cell A1 is no longer a dependency.
De-register cell with A1.
Once all values are changed, and changes to dependency tree noted, it's just
a case of updating the values of one or more cells, and then informing all the
dependent cells that they need to update.
- Copying a range of cells.
This would appear to be a variant of the above: First, a range is updated
(with values copied from another range, possibly with cell references
offset), and then dependencies are notified.
- Moving a range of cells.
Rather bizarrely, this is completely different from the instances above!
- There are 2 ranges which need to be added to dependencies
- The source range (where cells are being deleted from)
- The destination range (where the cells are going)
- The cells don't need to be copied value by value. Rather,
the moving cells register themselves in the appropriate Row
and Column, and eject any cells that happened to be there
first!
- (As you might imagine, because there is no copying, only moving,
there is no offset of references. Any existing references to the
moving cells will work just fine).
- Because the cell that has been clobbered will now cease to exist,
any nodes that referred to it must be notified of its passing.
They should
- Replace their reference to the clobbered node with a Null or
Error value.
- Set their value to an Error value.
- Pass this error on to dependent nodes, which should also now register
an Error.
- Moving a range of Rows or Columns
Just as above, the range is simply reregistered at a new location.
Of course, instead of just clobbering the destination range, it would
be very easy (easier even) to insert the range at another location.
But... both source and destination ranges will still have to be
checked, as we may have moved cells that were part of a range calculation,
or which now enter a range calculation.
- Deleting a square range.
To delete a square range in the grid, one might think it would be enough to
just blank the values of every cell in a range: naively, this would be
equivalent to the simple update above (1),
but it's preferable to also delete references to the cells being deleted,
so actually this is the same as the 'clobbering' section of Moving ranges (3).
I'm not planning to support the "shift cells left" or up behaviour offered
by, for example, Microsoft Excel. It's occasionally useful, but I'm not
convinced it's worth the implementation bother.
- Deleting a range of Rows/Columns.
However, deletion of rows and columns will be supported almost as
simply as just removing the required range of Rows/Columns.
Note that in this case we don't clobber every range that intersects
the Deleted range.
- If we've deleted a range in the middle of an existing range,
then we need take no action (beyond scheduling that range for
update in the dependency graph).
- If we've deleted a range that overlaps the edges of an existing
range then we could
shift the edge of the range to the next remaining row/column.
For example, if we delete column B, then a range like
B5:E7 might change to become C5:E7 instead.
It would obviously also be scheduled for update.
- If however we've deleted a range that completely surrounds
the existing range, then that range will be deleted and scheduled
to be clobbered.
- Inserting a square range of cells.
e.g., and shifting the cells at the destination right or down.
This will not be supported. Because
- Can be confusing and cause cells to become out of synch with cells
in other rows.
- Would be more bother to implement than it's worth.
- Inserting rows/columns.
Interestingly enough, this could be done simply by inserting the row or
column into the Grid, and renumbering.
The references of cells after the insertion will have changed Address, but
this can be lazily calculated as needed.
This simple implementation is only assured if I don't have any formulas
that count on the layout rather than the existing cell values.
I'm assuming that things like SUM,
AVERAGE etc. will only operate on cells with values. This means
that inserting blank rows into a range would have absolutely no effect.
If, however, I have any formula that either
- Operates on blank cells
(putative COUNT_BLANKS, AVERAGE_INC_BLANKS functions)
- Translates into the address of the range (ADDRESS)
then those formulas might have to be updated for such insertions.
For implementation simplicity, I'm going to stick my head in the sand,
and assume that these formulae do not exist for now.
May 22, 2003
Cell evaluation: yet more thoughts
I'm getting dangerously near to writing some code... ;-> but I keep finding
myself coming back to the design of the evaluation model.
I've been in contact with Michael Zemljanukha, the author of
Microcalc, which has been
very interesting: I'll write more about it soon. But for now I wanted to
comment on an issue Michael mentioned with the current version of Microcalc:
The main problem of existing algorithm is that it
doesn't support "massive" updates, when there are many cells changed as it
may happen when you insert a row/column (the most
possible case) or copying a range of cells.
This is clearly something to think about which I've been avoiding: the impact
of updating or moving a range of cells and, a related issue, updating a single
cell which happens to be inside a range which is referred to by a formula.
A
B
1
100
200 <<<
2
300
400
3
500
600
4
5
=B2 * 4
=SUM(A1:B3)
In this table, when we change the cell B2, two cells have to change:
- not only A5 (which refers to B2 explicitly)
- but also B5 (which refers to the range A1:A3 that
contains B2)
One strategy would be for every cell to point to every range that contains
it.
This is effectively the model that I've already described, but with one
difference: the dependency graph can contain node classes representing
ranges. Both Cell and Range classes would, then,
conform to an interface (GraphNode) which exposes methods
(.edges() etc.) that allow them to be iterated in a Breadth First
Search and topological sort). However, only a Cell object would be
asked to re-evaluate itself.
Though this could work, it is inefficient on a number of counts:
- Every cell needs to reference every range that contains it. (Storage)
- If I create a formula that references a range =sum(A1:E500),
I now have to iterate over several thousand cells, adding a reference
to the new containing range, even before calculating.
(Too much like hard work)
I think we want to lazily evaluate which ranges a cell belongs to
only when we need to.
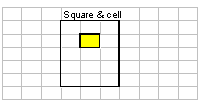
In this image, the yellow area represents a group of cells which have changed.
The orange areas are ranges:
- Completely inside the changed range. Any formula that refers to the
range will have to be recalculated.
- Completely outside the cha"http://www.symbiandiaries.com/archives/osfameron/eval_3.png"nged range. Not affected.
- Overlapping: the range will need to be recalculated exactly as per 1.
Some thoughts:
- The Grid will need to maintain a collection of Range
objects.
- Range objects will have a method .intersect(Range r)
which will either
- return the intersection of 2 ranges
- return null if there is no intersection
- Every time a range of cells is updated, it will be compared against
every Range stored by the Grid. If the 2 have an
intersection then the Range will be added to the dependency graph.
- As the range being updated could be a single cell, we could
handle this by
creating a range consisting of just that cell to compare with. But I think it
may be more elegant to have the Cell class implement an interface
AbstractRange shared with Range objects?
- As we do the BFS walk of the dependency-graph, every time we visit a new
node, we need to check which Ranges it is in. This will also need to be
checked for circularity.
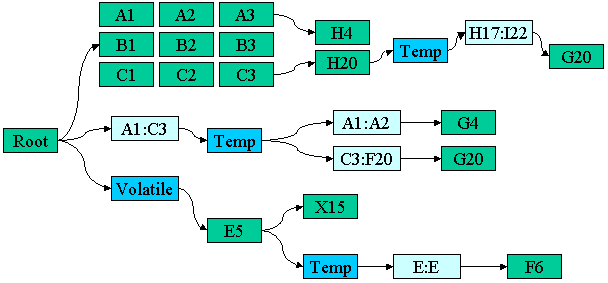
I think that the process for updating a cell or group of cells will be
- Start with a graph node Root
- Add an edge from Root to every cell in the updated range.
- Add an edge from Root to any ranges intersecting with the updated range.
- Create a HashTable that also contains these items, to show
that they have already been "seen".
- Start the BFS iteration. For every new (e.g. "unseen") node that is
visited (be it a Range or a Cell)
check for overlapping Ranges. If there are any, then create an edge
first to a Temporary node, and then add edges from the Temporary
node to these Ranges.
The reason for creating a temporary node is that Range dependencies of a Cell
or a Range may change, and it's easier to create a single disposable node
to store them in briefly. (I suppose that this node could be cached and
only recalculated when necessary?)
Though I don't know if it's that important for Gilgamesh to support
volatile functions (like TIME and RANDOM, which
change every time the sheet is recalculated), all we have to do is to create
a node called Volatile which contains edges to any cell that contains
a volatile function.
Putting this all together, we get something like:
May 08, 2003
units
Came across Mark Jason Dominus's program
units,
which converts intelligently between human-specified scales.
(To compare to Frink)
Cell evaluation order
I've given this some thought and I'd been planning to get to this shortly, but
Alan Eliasen asked about it.
Alan gave a good link to Bob Frankston's
notes on the development of VisiCalc which also mentioned the evaluation
strategy they used:
Row order
Every time a cell is changed, loop through all the other cells updating them
once.
(An obvious alternative strategy is column order).
I'd heard of this, considered it briefly, and rejected it because this brute force
sounded inelegant, involving too much unnecessary work, especially for a larger
sheet.
Cascading updates
Originally, I'd planned for every cell to keep a list of pointers to dependent
cells (any cell that references it).
.-->B--.
/ \
A +-->D-->E
\ /
`-->C--'
When a cell is updated it will ask its dependent cells to update themselves.
Those cells in turn may update other dependent cells: this means that there is
a risk of circular referencing. So when I trigger the update I pass a
reference to a Collection (an ArrayList, Vector, or HashTable) adding the
original cell.
Of course, the same cell may need to update itself 2 or more times: this is OK,
as long as each time is on a different evaluation path. Here, D is
evaluated twice, but the cell-paths passed in are not circular:
(A)
.-->B--.(AB)
/ \ (ABD)
A +-->D------>E
\ / (ACD)
`-->C--'(AC)
(A)
Each subsequent cell checks if it is in that Collection before appending
itself to it. If it's already there, then this calculation path was circular,
and should generate an error. Here, cell C is asked to recalculate in a path
that already includes C:
(A)
.-->B--.(AB)
/ \ (ABD)
A +-->D------>E
\ / (ACD) |
`-->C--'(AC) |
(A) ^ /
| /
`------------'
(ACDE)
^
Circularity
Error here!
Natural order
This would work, but means that the same cell may have to recalculate more than
once, which could be inefficient, and might have some pathological cases.
It would be best to calculate in which order the cells have to be updated,
and then calculate them all once only. This is called 'natural order'.
And while you might think that calculating the order to evaluate cells in
was a tricky task, in fact there is a simple way to do it.
If you have a Computer Science background, you might recognize the dependency
diagrams above as a DAG, or Directed Acyclic Graph. And you might
realize that all we have to do get the evaluation order is to run a topological
sort on single-source DAG. If you don't understand that, then read on!
Graphs in computer science aren't the same as the nice bar-charts and diagrams
that non-geeks might expect them to be. They are just
- a collection of nodes (like our Cells)
- connected by edges to other nodes. (the references to other cells)
- The connections can be directed, which means they go in one
direction only (Cell A1 is a dependency of B5. But not the other way
round!)
- The graph can be acyclic if there are no paths which come back
on themselves (e.g. there are no circular references).
- A graph can have one or more sources, which is the entry point
into the graph. (In the diagram above, I showed a graph with a source at
Cell A. But of course if we were updating Cell B, C, D... Z, we would
use the part of the graph that started with that cell. That sub-graph might
not go to every node in the full graph).
So, the diagrams on cell dependencies represent Directed Acyclic (hopefully)
Graphs with an entry point at a Single Source which is the first Cell to be
updated.
Topological sort is a sorting technique that involves visiting each node
and the nodes it links to in turn (often called 'traversing' the graph)
in such a way that all dependent nodes are listed last.
You can walk the graph in 2 ways, "Breadth first" (BFS), or "Depth first" (DFS).
This is actually rather intuitive:
- Breadth-first means visiting all the nodes from the Source
node. Then all the nodes pointed to from all of these nodes. And so on.
- Depth-first means starting with the Source node, and diving all the way
down first one branch, then the next.
An accurate & elegant description of the topological sort algorithm, then,
is to do a depth first search and list the nodes in the order in
which they are last seen. The easiest way to understand this is with
an example:
.-->B--.
/ \
A +-->D-->E
\ /
`-->C--'
Starting with cell A we follow this branch to its end (depth first)
- A
- A B
- A B D
- A B D E
and then start on the other branch
- A B D E
- A B D E C
- A B
D E C D
(now that D has appeared later, we scrap the earlier entry)
- A B
D E C D E
Leaving
- A B C D E
If none of this makes sense, you're in good company. Certainly, I found
a lot of this baffling, and I had better teachers than me. (Specifically,
I read the Graphs section in Algorithms with Perl which is quite
extensive and clear, and offers nice implementations - albeit not in J2ME).
I've come across one book,
Introduction to Data Structures and Algorithms with Java, which I didn't
buy because it is old (in Computer book terms), and also looks like it spends
a lot of time looking at non-graph related things like AWT, which makes it
seem a bit incoherent).
Maybe this book
is good?
I think it's also worth looking at language-generic
introductory guides to Computer Science.
Beginning an implementation
It is fairly trivial to implement a minimal graph-walking algorithm
doing a simple recursive tree walk. Of course
it's often more elegant to do this iteratively. (For example
Dominus will
have some chapters on this in his forthcoming book).
Using the Iterator interface is also Java best practise. (Though I think J2ME doesn't define the Iterator interface).
Here's some basic setup for a basic Node class.:
import java.util.*;
public class Node {
private Vector edges;
private String name;
public Node(String name) {
edges = new Vector();
this.name = name;
}
public Collection edges() {
return edges;
}
public String toString() {
return name;
}
}
It is fairly easy to add a DFS Iterator class:
import java.util.*;
public class DFS implements Iterator {
private Vector iterators;
private Node curr_node;
private Iterator curr_it;
public DFS(Node source) {
curr_node = source;
curr_it = curr_node.edges().iterator();
iterators = new Vector();
iterators.addElement(curr_it);
}
/** The class works by keeping a stack of Iterators
* for each fork in the Graph. The hasNext() method
* checks if any of the Iterators in the stack have
* any more Nodes to return (e.g. if they return true
* on hasNext()).
*/
public boolean hasNext() {
while (! iterators.isEmpty()) {
curr_it = (Iterator) iterators.lastElement();
if (curr_it.hasNext()) {
return true;
}
iterators.remove(iterators.lastElement());
}
return false;
}
/** Every time a new object is selected, add the
* Iterator for its own edges to the stack.
*/
public Object next() {
Node next = (Node) curr_it.next();
Iterator new_it = next.edges().iterator();
iterators.addElement(new_it);
curr_it = new_it;
return next;
}
public void remove() {
; // just to fulfil requirements of interace.
}
}
(Adding checking for cyclic paths in the graph is left
as an exercise to the reader...)
And of course, add a method to the Node class:
public Iterator DFSIterator() {
return new DFS(this);
}
Now it's easy to create the Topologically sorted dependency list
(add this method to Node class).
Iterate through the Graph, adding the latest node to the end, first of all
removing any previous occurrences:
public Vector dependencyList() {
Vector v = new Vector();
v.add(this);
Iterator it = this.DFSIterator();
while (it.hasNext()) {
Object o = it.next();
if (v.contains(o)) {
v.remove(o);
}
v.add(o);
}
return v;
}
Coming up soon:
- Maybe I'm wrong about optimization of row-based vs natural?
- Why we might want Circularity
May 04, 2003
Pluggable Evaluation Engines
After some further thought, it seems clear that the Evaluation Engine itself
should be loosely coupled from the Spreadsheet Container Model, that is to say, Grid, Row, Column, & Cell structure,
and from things like Evaluation order processing (to be blogged shortly).
I'm not sure if I've thought about, and indeed written this up, as coherently as
previous entries: comments and discussion welcome...
The Grid will maintain the containers (Rows & Columns), which in turn
maintain Cells. Cells contain a Value and a Formula.
The Formula is turned into a Value by the Evaluation engine. This means that
the representation and the semantics of Values are limited by the Evaluation
engine. So are the Data Type inferencing rules. For example:
- If I were to use Frink as an Evaluation engine, then the Values used by the
spreadsheet might be
- 5 metres
- 1 jeroboam
- 40 acres
If I were to input 40 acres into a Cell, I would expect the Spreadsheet
to infer it as 40 acre units, whereas if I input The quick brown fox I
would expect an inference of the string "The quick brown fox".
Frink-based calculations would track units across calculations so
A1 * A2 where A1 and A2 were metre lengths would give a
result in square-metres. Multiplying a length by a voltage might give
a semantic error.
- The simple evaluation engine that I was planning would contain some basic
data types like
- 10.4 (number - Fixed Point)
- 20 (number - Integer)
- 20% (number - Percentage)
- $20.00 (number - Currency)
- 4/5 (date - 4th of May. Not 0.8!)
- The quick brown fox (string)
My simple evaluation engine would track the type of a number (e.g.
A Currency (number) + an Integer (number) would remain a currency
amount. Trying to multiply a String and a Date might give a Semantic
error.
- Other evaluation engines (such as Simkin and others) may have other
semantics and representations which allow and limit them to certain types of
calculations and evaluations.
However, whichever Evaluation engine I use does not make any impact on
the way that I move, cut, paste, and insert the building blocks in the Grid.
Effectively, there will be a simple interface that an Evaluation engine will have
to follow:
- A Cell may be asked to recalculate itself.
- A formula may be asked to return its String representation.
(As a formula will very likely have references to Cells and Cell ranges, the formula would also be expected
to display the current address or name of those ranges) e.g.
A5 + A6 or quarterly_sales_results_total * 4
- A value may be asked to return its String representation.
- A formula may be asked to return a Collection of dependencies after it
has been parsed.
(The evaluation engine will use this in calculating the evaluation order of cells).
- The Data model will never want to be passed an actual Value (in fact, it
couldn't know what to do with one if it got it!), only the String representation of it.
This loose coupling is a relief, because it means that I could start with a stub
evaluator (which does something really simple like summing Cells with integer values), and develop and test it thoroughly before moving onto formula
calculation.
I think that the User Interface will be more tightly coupled to the evaluation engine. For example:
- Formats may be available which filter the value. For example, a
Value representing 3.141592 might be shown as:
- 3.141592
- 3.142
- 3
- 3.14%
- $3.14
- 03.14
- 22/7
- PI
The User Interface must have access to some details about the value to know
that it represents a number.
- If the Value is a Date, I may be able to tap on a DNL (Direct Navigational Link) which brings up a Calendar chooser for me to replace with another date.
Hmmm, I wonder if all this means is that the Expression evaluator must conform
to an interface which allows the UI to query it about the type of Value of a given
cell, and to request it to format the result in an appropriate way?
Loose-coupling between UI and Data Evaluation would have some benefits, but I wonder if it as clear cut as keeping the Container model separate?
May 01, 2003
Expression evaluation: Simkin, Micromath, Frink
I've come across some other projects, and had to re-question whether Gilgamesh will have its own expression evaluator as I suggested
above. All comments welcome!
Simkin
At the pub-meet I met Simon Whiteside, enthusiastically promoting his Open
Sourced scripting language, Simkin.
I'd read the blurb on it before, and thought "huh?" before bookmarking it
and moving on. Simon says that Simkin sometimes gets this reaction, but has
convinced me that it's worth looking at in more detail!
It's lightweight
(50K jarfile), is implemented in both C++ and Java, and has been ported to
J2ME.
it is also an expression evaluator which, if I understand rightly, can easily
be customized to include custom objects. So, for the purpose of Gilgamesh,
something like
=A5 * 4 + sum(B2:C5)
Could actually get parsed as a Simkin expression which refers to Gilgamesh
objects for the Cell (A5) and Range (B2:C5).
Though I'm happy to steal, um, leverage existing code to parse formulas
(as I wrote above, I was quite happy to leave this to someone else!), I guess
that it will have some impact on Data representation, and on formatting of
Cell results. (I'll try to write up my initial thoughts on these soon).
So I have to look into any existing code and API before I commit.
Some good
documentation
from the Simkin site itself, including links to off-site articles.
If I do use Simkin, I should also think about using it as an on-board
extension language!: I hadn't thought about having an scripting language
in Gilgamesh, because it seems like unnecessary bloat, but if I get it for free
it's worth thinking about.
Micromath
Some time ago, I looked at the Micromath library, which powers
Microcalc. Microcalc is one of the big influences
on this project, in terms of inspiration, and a benchmark to try to compete
with. Rafe has suggested it'd be worth getting in touch with the Microcalc
development team (Michael Zemljanukha) to discuss the two projects: now on my
todo list!
J2ME doesn't support Floating Point maths. Micromath gives Fixed
Decimal maths support, and is a very compact Java library. However I'm leaning
towards using the MathFP library (mainly because it has better documentation.)
Frink
Alan Eliasen has posted a comment mentioning his project
Frink.
From a first quick read of the (nicely detailed) docs, you could describe
it as a mix between an expression evaluator that knows about the world, a
miscellany of facts and figures, and a programming language that, like Perl,
tries to DWIM ('Do What I Mean') in some really clever ways.
In one of the wonderfully whimsical examples in the docs, he calculating the
rainfall in the Biblical Great Flood using the formula:
depth = 29030 feet + 15 biblicalcubits - (2.4 inches/ year 4000 years)
Frink knows about feet, and inches, and years, and um... biblical cubits.
Not to mention currencies, current and historical!
It also tracks the unit
type of a calculation, making sure that you do sensible things with them:
e.g. you can add 1 mile + 4 metres but it wouldn't make sense to
add 1 mile + 4 volts. (2 metres) * (2 metres) will actually
know to return an area in square metres!
I love this idea: surely this should be mainstream?
Alan noted that he'd thought about using this in a Spreadsheet: I would love
to see that happen, and I have to admit I'd be seriously tempted to use it in
Gilgamesh. On the minus side:
- Apparently it can be a little heavyweight: the data file is already
large, and when it is (very cleverly) parsed to get all the relationships
between the different data types, the resulting data structure is quite
complex. Update: See Alan's comment for some clarification.
- Though it's been ported to constrained devices, including my target
platform, the SonyEricsson P800, it's been ported to PersonalJava rather than
MIDP (see above).
-
I don't think it's designed to be plugged in to object models, worth
investigating though.
- It isn't open source. See the
FAQ for
a reasonable reason why not.
April 26, 2003
Formulas
I hinted in the entry on the Grid that each cell would contain a list of cells
that it refers to in formulas.
A
+------+
1| 1 |
+------+
2|A1*2 | <-- references: A1
+------+
3|A1+A2 | <-- references: A1,A2
+------+
But of course this is an oversimplification. We don't just need a list
of cells that we reference: we need to know how they interact with the formula.
The formula will need to be parsed into a tree of data relating
- Functions
- Cell references
- Constant data (numbers, strings, dates)
Some examples
(Don't pay too much attention to the pseudo-syntax)
A1+A2
- function(+)
- ref(A1)
- ref(A2)
if(A1==23 then "Yes" else "No)
- function(if)
- function(equals)
- ref(a1)
- constant(23)
- constant("Yes")
- constant("No")
The last example shows a more complicated example, demonstrating
that parsing the syntax could be quite intense.
Of course, even a standard, commercial product like Excel simplifies
the syntax by making it more functional:
if(equals(A1, 23), "Yes", "No") // Excel syntax
As you can see, this is much more easily translated into the parse-tree above.
S-expressions
The easiest (for the implementer) way of having formulas easily parseable would
be to use the Lisp syntax of S-expressions. 99% of Lisp commands are written
like this
(function arg1 arg2 arg3 ...)
Converting the formulae above:
(+ A1 A2)
(if (equals A1 A2) "Yes" "No")
It looks a bit odd if you're not used to it, but it's trivial to build the
parser. My first design idea is this:
- If you write a formula beginning with parenthesis "(", then it will be
parsed as an S-expression.
- If you write a formula beginning with an equals "=", just like Excel and co,
then it will be parsed more cleverly.
=1 + 2 // arithmetic operators come inline
=function(arg, arg) // functions as standard
=A1 // reference unchanged
- The S-expression parsing will get implemented first: we can worry about
the syntactic sugar later
Whichever way the formula is specified, it will end up being parsed as
- Reference to a Function object
- Zero or more argmuents
Of course, any of the arguments may also be Formula objects in turn, thus
creating the parse tree.
(if (= A1, 23), "Yes", "No)
- Formula:
- Function: if
- Formula------------.
- Constant: "Yes" \
- Constant: "No" \
- Function: =
- Reference: A1
- Constant: 23
The Function class will have a simple interface something like:
public abstract class Function {
public String display;
public boolean CheckArgs(Value[] args) {
// ... (filled in by subclass)
}
public Value execute(Value[] args) {
// ... (filled in by subclass)
}
}
and is extended by subclasses like so:
public class EqualsFunction extends Function {
public EqualsFunction() {
display = "=";
}
public boolean CheckArgs(Value[] args) {
if (args.size == 2) {
return true;
} else {
return false;
}
}
public Value execute(Value[] args) {
if args[0].equals(args[1]) {
return BooleanValue.TRUE;
} else {
return BooleanValue.FALSE;
}
}
}
Common framework for data
NB: I'm assuming that all the possible data-types
(Booleans, Formulas, Arguments, Strings, Cell References) inherit from
a parent class (here Value). That's because we need to be able
to pass them around, store them, and use them consistently.
This might well be too heavyweight for being on a J2ME constrained
device. But I think it will have its advantages: we'll see as we go on and
try to optimize later if we need to. More on this topic later.
April 25, 2003
Designing the Grid
One of the most important data-structures to determine for a spreadsheet
application has to be the Grid. It's what gives us the concepts of
"Rows" and "Columns" of cells, and gives us a nice way of formatting
related items like records of data into tables.
2-d array
The naïve way of implementing this (and I mean the way that I first
thought of ;->) is to use a 2-dimensional array. That is to say, if the
grid is 30 x 30 we'd have a grid something like:
1 2 3 4 5 ..30
+-+-+-+-+-+---
1| | | | | |
+-+-+-+-+-+---
2| | | | | |
+-+-+-+-+-+---
3| | | | | |
+-+-+-+-+-+---
4| | | | | |
:+-+-+-+-+-+---
:| | | | | |
30 : : : : :
Array of arrays
Of course, in some languages, such as Java and Perl, this is implemented
internally as an array of arrays. Though it's declared and used as if
it was really a grid, in fact each individual array can contain a different
number of elements.
+-+ +-+-+
|1|->| | |
+-+ +-+-+
|2|->| |
+-+ +-+-+-+-+
|3|->| | | | |
+-+ +-+-+-+-+
|4|->| | |
+-+ +-+-+-+-+-+
|5|->| | | | | |
+-+ +-+-+-+-+-+
|6|->| | |
+-+ +-+-+
: : :
Already, this seems to have some advantages, in that some rows may have more
data than others. We don't have to store cells that don't exist (i.e. it's
a sparse data-structure).
Once we start thinking about rows of data, this leads to some other
considerations:
- Add more rows to the end of the grid
- Delete a row
- Insert a row in the middle of the grid
All things which one does reasonably often with a spreadsheet program.
If we have a row-based model rather than a grid based one, then it's easy
to just add the row using the standard List-manipulation techniques of,
for example, the Vector class.
Cell references
Most of the power of spreadsheets comes from the fact that cells can reference
other cells:
A B C
+---+---+-----+
1| | |A2+B2|
+---+---+-----+
2| 3| 5| |
+---+---+-----+
If we add a row
A B C
+---+---+-----+
1| | |A2+B2| <--
+---+---+-----+
2| | | |
+---+---+-----+
3| 3| 5| |
+---+---+-----+
I'd expect the reference in cell C1 to now point to A3+B3.
Hopefully there is a more elegant way for us to do this than to go through
every cell in the grid updating the formulas.
References to cells, not to addresses
The formulas shouldn't contain references to a particular address, but to
the Object of the cell. (I'm assuming basic familiarity with OO, especially
Java here).
public class Cell {
/** Cell has an Array of other Cell objects which it refers to */
Cell[] references;
}
Just because we've added or moved a row here or there doesn't change the
other Cell objects, so we don't have to update the addressing at all:
of course this implies that the referenced cell has a way of
finding out its own address eventually:
Cells know which row and column they're in
The best way for the cell
to know its own address is to keep a reference to which row and column it's
in. The row and column will know which number they are.
+-+-+-+-+-+-+-+ B
1| | |X| | | | | +-+
+-+-+-+-+-+-+-+ | |
^ +-+
/ |X|
/ ->+-+
+-+ / | |
|X|------------ +-+
+-+
e.g. Cell object maintains references to its Row (Row 1) and
its Column (Column B). Both the Row and the Column also contain
references to the Cell object.
public class Cell {
Line row;
Line col;
Cell[] references;
}
If the Cell object needs to know its address, it can query the Row and the
Column. All that needs to happen when Rows or Columns are inserted or moved
is for them to be renumbered. This implies that the Grid contains
- A list of rows
- A list of columns
The grid will manage the renumbering of the list whenever changes happen.
All the individual Line needs to do is to maintain the position
that it is in the list.
Deleting a line
Of course there is some additional complexity here:
A B C
+---+---+---+
1| | |=A2|
+---+---+---+
2| 33| 12| |<-- delete this line
+---+---+---+
- Delete Row 2
- For each cell in the row, delete the cell from the relevant column
- 33 (delete from column A)
- 12 (delete from column B)
I'd originally hoped that we wouldn't have to manually loop through each
column by using a feature called Weak References. A Weak Reference
is a reference which automatically disappears when all the other references
to it have gone. However, though Java supports the WeakReference
class, J2ME (The minimal subset of Java that runs on constrained devices
like Symbian phones...) doesn't. I've already run into quite a few failed
implementation assumptions because of this...
But though we don't need to notify dependent cells when a cell's address
changes, we do need to notify when the cell itself changes (or as in
this case, is deleted).
A B C
+---+---+---+
1| | |=##|<-- error!
+---+---+---+
Generic deletion of a line
(e.g. row OR column)
- Delete the line
- (renumber the list of lines)
- For each cell in the line
- delete the cell from the relevant perpendicular
line.
- Notify any dependent cells that this cell has now been deleted.
Link: Validating the Unit Correctness of Spreadsheet Programs
Validating the Unit Correctness of Spreadsheet Programs via Lambda the UltimateGrids and Subgrids
I've been thinking a while about Lists actually being represented as Grids which are magically embedded into the top-level Grid. After waffling about it in the last 2 entries I'm ever more convinced that this is the way to go.This is potentially much more complex than I'd planned, but it makes some things simpler. Some notes:
- Though the data will be stored in the sublist, in the display the cells will be contiguous to the main grid (and in fact could be selected by the main grid too). e.g. B5 could be Sales[1] (e.g. row 1 in column Sales).
- For convenience, the UI will show list headers instead of A B C D etc. if you are in the middle of a list. (In Excel you have to explicitly request this behaviour with Split Window and Freeze Panes).
- If you tried to copy a cell from a List containing a reference to a column (=Sales_Result*2) to outside the list, e.g. where this column doesn't exist, the cell should set itself as an error.
- (On the other hand, the main columns A B C D etc. should be referrable within the sublists too).
- Sorting a sublist will be easy because you can just order the rows in the grid. Otherwise you'd have to buffer and copy cells around which would be a pain. (Or only sort by whole-row, which is admittedly very common: for example Excel still reverts to whole-row sorting under some circumstances, like when you share a worksheet!)
- Curses: MIDP doesn't appear to have a sort method on Vectors! Time to look at those algorithm books again...
Spreadsheets and $Horrible$Syntax
Yuk I hate this spreadsheet syntax:$A$1:$F$100I've always hated it, and I don't want to have to use it in Gilgamesh. On the other hand it's clear why it's needed: the kind of formula I described in the last entry. When copying or filling cells, you want some of them to offset their references and some of them not to. By placing the dollar ($) sign before any reference that doesn't change, you have fine grained control over how this is done.
My thoughts on this are as follows.
- Gilgamesh will be a light-weight spreadsheet designed for small devices. I don't want to sacrifice power if I don't have to, but if I can get simplicity and useability by sacrificing it then so be it.
-
If I've referred to a cell in the same row, then it's likely
that I'll want the reference to offset downwards.
Whereas if I've references a cell in another row then it's
likely to be a constant value. So I can use the heuristic:
- Offset any references that are in the row.
- Keep references outside the row fixed.
-
On the other hand, if I've referred to a constant value,
then I would probably have been better off giving it a name.
=150*A5 tells me nothing about the formula, whereas
=150*GBP_to_EUR gives me a named reference (which
won't be offset) and tells me that I'm converting 150 pounds Stirling
into Euros.
- Offset any direct references
- Keep references to names fixed.
-
I don't think I've ever seen any reason to offset an
entire range. This behaviour causes me nothing by
irritating bugs like the above.
- Consider only ever offsetting single-cell references.
- This is open to reasoning: if your spreadsheet usage is different to mine and you find this useful, let me know.
-
With the concept of row-scoped names, we could insist that
no offsetting is ever done!
- References to cells on same row actually only maintain a reference to the corresponding column. The actual cell referred to is dynamically calculated.
- References to actual cells are never offset.
- A1: =B+B1 would be equivalent to =B1*2, however if filled down (or moved) A2: =B+B1 dynamically becomes =B2+B1.
- I originally thought that this would have an impact on the evaluation
ordering (Previously described in detail).
But in fact it should be minimal.
When the formula is calculated it will return references to the actual
cells (B1, B2) involved. However, internally it will only store the
reference to the column. This means that every time the Orderer notices
a change it will deal with registering and deregistering the Cell from the
evaluation tree as appropriate.
The only additional complexity is that the formula becomes slightly range-volatile. That is, it is affected by movements of the cell between lines, but not by insertions/deletions in the Grid that happen to change the line's address. This could easily be represented by an additional special node in the evaluation graph.
Excel's dynamic named ranges considered harmful.
Though I'm stuck in nitty-gritty implementation work, and this isn't a priority for some time yet, I thought I'd whine for a moment about Microsoft Excel's dynamic ranges.
Lists
I usually use Excel for managing lists. Lists have a header row with the title of the column ("Name", "Country", "Score") and any number of rows underneath them. You will often want to write formulas that act on a whole column: for example- SUM: add up the figures in a column
- VLOOKUP: look up a value in one column and return its corresponding value. (For example Name -> Address lookup)
- Insert a new row in the middle of the range. (Because the range runs from the first row object to the last row object this just works.)
- Start inputting the data on the next row after the last row in the list. This, on the other hand, won't work. The range that you referred to in the formula doesn't change. So you're going to have to dig up any formulas that need to be changed and modify them by hand.
Dynamic Named Ranges
Excel's answer to this is Dynamic Named Ranges. From the useful OzGrid page on the subject:Possibly one of Excels most underutilized aspects is its ability to create dynamic named ranges that will expand and contract according to the data in them.Let's see how you create a named range.
Go to: Insert>Name>Define and in the Names in workbook box type any one word name (I will use MyRange) the only part that will change is the formula we place in the Refers to box.OK so far, note that you can't just access a dynamic range from the formula bar, they have to be named (hence "dynamic named range")... Now let's see an example of a formula defining a dynamic range:
1: Expand Down as Many Rows as There are Numeric Entries.And at this point you might already understand why this functionality is "underrated" ;->
In the Refers to box type: =OFFSET($A$1,0,0,COUNT($A:$A),1)
The OFFSET() function takes these arguments
- the initial range ($A$1)
- the head row offset (0 - the row remains 1)
- the head column offset (0 - the column remains A)
- the tail row offset (COUNT($A:$A) - count the number of non-blank cells in column A and offset the end of the range by that number)
- the tail column offset (1 - being the width of the new range)
3:Expand Down to The Last Numeric EntryThis is quite clever in a horrible-kludge way. MATCH() with these parameters finds the largest number in an ascending list that is equal to or less than the parameter. As it's expecting an ascending list, I guess that it optimizes by starting the search from the end and looking backwards. Because the first number that will be found is bound to be smaller than the very large number provided, this hack will work.
In the Refers to box type: =OFFSET($A$1,0,0,MATCH(1E+306,$A:$A))
If you expect a number larger than 1E+306 (a one with 306 zeros) then change this to a larger number.
I don't want to come across as criticising the OzGrid site or the useful examples that it provides. Certainly for the advanced searches that it goes on to describe ("Expand down one row each week", etc.) this syntax is flexible and powerful. But it's fairly clear from the entries that I quoted that a main use is to sum or manipulate columns in a list. And this really should be simpler! Indirection like used in OFFSET, coupled with bizarre hacks to locate the endpoints is liable to be tricky to use, debug, and maintain, and cause subtle errors.
A new hope
I'm thinking along these lines for Gilgamesh:- Every list will have dynamic named ranges created automatically for each column.
- These ranges will usually be named after the header row. For example a Column header which has "Q4 Sales" might generate a dynamic range called "Q4_Sales".
- An external formula can now simply do =sum(Q4_Sales).
- Of course if someone had already registered a range called Q4_Sales we'll have to do something appropriate mumble mumble handwave handwave ;->
- If we change the header text to "Q4 Sales figures", the range will rename itself to "Q4_Sales_figures", and because all referencing formulae are pointing at an object, not a String, they will magically have rewritten themselves (=sum(Q4_Sales_Figures)).
Single cell ranges
And something that might be more controversial: single cell dynamic named ranges.- Within a list, you are more likely to refer to a cell within your row
than to a whole column. For example, consider the columns
- First Name
- Last Name
- Full Name
Full_Name: =First_Name+" "+Last_Name
is about as clear as you can get, and certainly clearer than the kind of thing I write in Excel (=A5+" "+B5). So, within a row in a list, names will be scoped by default to the row itself. -
Of course you might want to be able to refer to a whole column, for example
to compare a score with all the competitors (=(Score - AVERAGE(Score))/100)
But this won't work: how can we tell that the first 'Score' is a range value
but the second is a single value?
I think it would make sense for a column in a list to take on the semantics of a column in a grid. So how about (Score - AVERAGE(Score:Score))/100)? The construct
: is parsed as a column range (A:B etc.) so this is relatively intuitive. But it's ugly, and it's a lot of typing. Actually, on a pen-based device like those targeted by Gilgamesh it's a lot of hand-writing recognition ;-> Perhaps we can assume that a column range where one column is omitted is actually a single column: (Score - AVERAGE(Score:))/100
I had considered going the Perl way and having an array sigil (Score - AVERAGE(@Score))/100 which stands out more. But I like the idea of treating columns of a list just like columns of a Grid. After all you can sort by them, which is an extension of this abstraction. It'd be nice to have consistency.
Consistency
If we want consistency, then I suppose that we should be able to refer to the Grid columns (A B C D E ...) within a row.C1: =A+B (e.g. is the same as =A1+B1)This could help resolve an error that I often make: when I was testing the Average example above, I filled in A1:A4 in an Excel worksheet, and then put in A1: =(A1 - AVERAGE(A1:A4))/100 which gave the right result. But when I filled down, I forgot as I so often do that this doesn't just move A1...
- =(A2 - AVERAGE(A2:A5))/100
- =(A3 - AVERAGE(A3:A6))/100
- ...
UPDATE (2003-06-19): From this page, I found this tip
[Ctrl][Shift][F3]: Automatically creates Named Ranges from the headers for the selected table of data with row or column headers.This seems to do something similar to what I want, but has some oddities, which I will play with
Modeling grid Ranges
I've discussed model objects like- Cell
- Column
- Row
- Range
- A 'square' range bounded by a Cell at the top-right corner, and another cell at the bottom-left corner
- A 'Line' range bounded by a Line (Row or Column) and another Line.
- The cell at the endpoint is no longer significant. We can delete that one cell without having to play around with the boundaries of the range. (Admittedly, this does have its conceptual disadvantages too). It's only when the row or column itself is deleted that we have to do some hard work.
-
More importantly, it is now very easy to model all the different
kinds of ranges in the same scheme:
- 'Square' range (A1:E5)
- Simply defined by the start-row and -column, and the end-row and -column.
- Row range (1:5)
- Contains a start-row and end-row. start- and end- column however are undefined (null,)
- Column range (A:C)
- Contains a start-column and end-column. start- and end- row however are undefined (null,)
- Cell (A1)
- Start- and end-column are the same (the column that the cell is in), as are start- and end-row.
- Single column (A)
- A column range whose start- and end- column are the same.
- Single row (A)
- A row range whose start- and end- row are the same.
- The entire grid(A)
- A row range whose row and column bounds are all undefined.
- Take two ranges, R1 and R2
which each have
rowhead,
rowtail,
colhead,
and coltail.
We want to get the intersection R3:
- Starting with Rows:
- Take R1's head and compare to
R2's head.
Return the maximum (that is, the one with the highest
position)
(e.g. R3.rowHead = max(R1.rowHead, R2.rowHead))
If either of the values is null, then return the other value. (If both are null, then return null)
- Take R1's tail and compare to
R2's tail.
Return the minimum (that is, the one with the lowest
position)
(e.g. R3.rowHead = min(R1.rowTail, R2.rowTail))
If either of the values is null, then return the other value. (If both are null, then return null)
- If the Tail is lower than the Head, (if R3.rowTail < R3.rowHead) then there was no intersection. Break at this point, returning null!
- Take R1's head and compare to
R2's head.
Return the maximum (that is, the one with the highest
position)
(e.g. R3.rowHead = max(R1.rowHead, R2.rowHead))
- Now do the same with columns.
- R3 is now a fully fledged Range objects with head and tail row and column values.
if (R1.intersect(R2) == R2) return true(The Range implementation in Java is going to include some rather lovely examples of .equals, .hashcode, .compareTo to make the API nice to read and use.)
For various reasons, it will sometimes be useful to know if a Range is a Line (Row or Column) range. This can be worked out quite easily when needed (they are the ones that have null values on one axis!), or it could be cached as a boolean property.
Cells
But Cells are a different matter. To contrast them to Ranges:- Ranges are stored directly in the Grid in a list (Vector?). Cells are stored in the Lines that they belong to.
- Cells are evaluable: they can be passed to the Evaluation Engine to be re-calculated. They also contain a Formula, a Value, and other data like the Parse-Tree for the formula.
My current thinking is that Cell should be a distinct subclass of Range. If the Range class is ever asked to create a single-cell Range (for example, through an intersection), then it should instead return a Cell object. (I think that in Java this would be done by having all creations of Range objects through a factory method which will return a Cell subclass object instead as appropriate). Effectively this means that there must be no single-cell Ranges. If a Range becomes single-cell at any point, then it should turn itself into a Cell instead. (Which means, in implementation terms, that it should pass on all of its dependencies onto the relevant Cell object, and then delete itself).
Hmmm, I'm not sure if I should make a distinction between Ranges and Cells. If I remember rightly, Excel doesn't have a Cell object - its Ranges have .Cells properties which return an enumeration of each single-cell range contained in the range. More thinking required.
Evaluation order and evaluation engines.
If you are following this thread of how evaluation order will be calculated (and if you are, please do let me know!) then you might think "Thank $deity that's over, maybe now he'll go and write some code". But though I think that the evaluation order Evaluation order and evaluation engines. calculation seems pretty sorted, I've now come to an interesting point: how do I build up the dependency list in the first place?What I mean is, how do we know that
=SUM(A1, A1:B2, Q4_Sales)contains references to the cell A1, the range A1:B2, and the alias (and there's another story) Q4_Sales? A naïve idea (and it's the one I first thought of) would be to do a search on the formula for anything that looks like a cell, range, or alias name, and add that to the dependency list. But of course it could find false positives
="A1+B1=" & C1would put the cells A1 and B1, as well as the required C1, into the dependency list. So some knowledge of the syntax of the expression language is required. Clearly, the Evaluation engine itself knows its language's syntax, and should be responsible for determining which nodes its formulae refer to.
Imagine that a cell contains (at least) these attributes
- Value (CellValue object)
- Formula (String)
- FormulaParseTree (ParseTree object)
- Dependencies (an array or Vector of Node objects)
- Cell object
- Range object
- Alias object ("Q4_Sales")
- Volatile
- Address
- =A1 + A2 (Cells A1, A2)
- =TIME + 1(Volatile)
- =Q4_Sales * RANDOM(Alias 'Q4_Sales', Volatile)
- =CONCATENATE(ADDRESS(ExampleCell), ": ", ExampleCell) (Alias 'ExampleCell', 'Address'-dependency node.)
Of course, the Engine itself has no responsibility over the evaluation order! (We want to do it right once. Whichever evaluation engine we plug in, it should concentrate on evaluating expressions. The evaluation-ordering class on the other hand will just worry about evaluation order, and leave syntax etc. to the Engine). So the process could look something like this: I'm hypothethizing two classes called Order and Engine to show the split of responsibility.
- User changes formula of cell A1
- Order checks which dependencies A1 already has.
- Order asks Engine to parse the A1.
- Engine parses the formula.
- (NB: Engine will have a reference to the relevant Grid object, and will request the object reference corresponding to the names - A1, A1:B5, Q4_Sales etc - from it).
- Engine updates Al's dependencies.
- Order compares the delta between Al's old dependencies
and it's new ones.
- If any dependencies are new, Order registers Al as a dependent of the appropriate Node. If any dependencies have gone, Order de-registers Al from the appropriate Node.
-
Order:
- ...creates a new Root node.
- ...creates an edge from Root to Volatile
- (but, as this is just a formula change, doesn't create an edge to Address.
- ...creates edges from Root to all cells changed (just A1 in this instance).
- ...scans every Range object and adds an edge from Root to any that intersect with the changed range (A1).
- Order now does a toposort starting from Root
- Order takes each cell in turn (e.g. in toposorted order) and passes just the evaluable ones (Cells, not Ranges, Names, Volatile, or Address) to Engine to evaluate.
- Engine takes the cell's parse-tree, calculates the result, and stores it in the cell's Value property.
Recalculating location-specific formulae
Thanks again to Michael for some interesting email discussion which has helped me clarify my thinking about this. But first, a recap:Recap
As discussed, Cells will not contain their (x,y) co-ordinates, only knowledge of which Row and Column they are in. Coupled with the fact that after a formula is parsed, references to cells/ranges are stored as Object references to the cell or range in question, certain actions can be done very efficiently.- Inserting a row or column
Inserting a row causes the following rows to renumber themselves. Any references will still point to the correct objects. The next time they are edited, the formula in the Edit box will reference the new name of the cell.(Compare to a scheme where each cell knows its own address: in this case, inserting a row would require cycling through all the subsequent cells in the grid to tell them to change their address).
- Deleting row or column ranges
After the various tasks required for any deletion (clobbering any cells and ranges completely contained in this range; scheduling other ranges which intersect with this range for update), all we need to do is remove the rows from the grid, and renumber subsequent rows. - Moving a row or column range
Any ranges that are completely contained in the range being moved will move along with it just like that! However, with ranges that intersect, we would need to schedule updates as with deleteion.
Location specific formulae
In a recent entry, I mentioned that I wasn't planning to support formulae like=ADDRESS(A1)which returns the address (in one form or another: "A1", or "R1C1", or "Q4_Sales"). Actually, that's not as wildly useful as it could be. How about
=OFFSET(Oranges, 1, 0)which returns the contents of the cell at offset (1,0) from the cell called "Oranges". Or, maybe
=CELL("A1")which returns the cell at address A1.
These formulae (and possibly other, better, examples?) could all be affected by insertions, deletions etc. of ranges. Because of this, I was very tempted not to support them...
And then it occurred to me that I'd missed a (very simple) trick. Add a Node to the update graph called "Address" or similar, which is equivalent to the "Volatile" node I mentioned:
Whenever the Evaluation engine notices one of these address-dependent formulae, it will request for the cell to be added to this node. The node will automatically get added to the "Root" update node when the update is any operation that could change a cell's address. Which brings me to the next entry on how the Evaluation engine will interface with all of this.In brief - J2ME plugin, spreadsheet FAQ
Via tomaspascual.net, news of an IntelliJ J2ME plugin.And from Michael Zemljanukha, the comp.apps.spreadsheets FAQ. Lots more to read [sigh].
Cell updates moves, insertions, deletions: evaluation and semantics,
I think that the dependency graph model is looking pretty good... but there's a bit more complexity to go... Let's look at the actual scenarios in which one or more cells are changed: some of these points are more or less arbitrary - it's interesting to compare these behaviours to the semantics of existing spreadsheets.- Standard Cell modification
Usually one cell modified by inputting into the cell (or into a formula bar at the top of the screen.)
But we might implement multiple cell update: e.g. by selecting a range and then inputting. Or by filling down (for example, a series). In these cases the value may need to be calculated (1, 2, 3, 4, ...) or a cell offset may be incremented (A1+1, A2+1, A3+1, A4+1, ...).
Note that the modification to a cell could change the dependency graph! The evaluation engine should parse the new formula, and compare the previous dependencies with the new.
- =A1*2 --> =A1/200 ... formula has changed, but the graph hasn't.
- =A1*2 --> =(A1+B1)*2 ... Cell B1 is a new dependency. Register cell with B1 as a dependant.
- =A1*2 --> "All gone" ... Cell A1 is no longer a dependency. De-register cell with A1.
Once all values are changed, and changes to dependency tree noted, it's just a case of updating the values of one or more cells, and then informing all the dependent cells that they need to update.
- Copying a range of cells.
This would appear to be a variant of the above: First, a range is updated (with values copied from another range, possibly with cell references offset), and then dependencies are notified.
- Moving a range of cells.
Rather bizarrely, this is completely different from the instances above!
- There are 2 ranges which need to be added to dependencies
- The source range (where cells are being deleted from)
- The destination range (where the cells are going)
- The cells don't need to be copied value by value. Rather, the moving cells register themselves in the appropriate Row and Column, and eject any cells that happened to be there first!
- (As you might imagine, because there is no copying, only moving, there is no offset of references. Any existing references to the moving cells will work just fine).
- Because the cell that has been clobbered will now cease to exist,
any nodes that referred to it must be notified of its passing.
They should
- Replace their reference to the clobbered node with a Null or Error value.
- Set their value to an Error value.
- Pass this error on to dependent nodes, which should also now register an Error.
- There are 2 ranges which need to be added to dependencies
- Moving a range of Rows or Columns
Just as above, the range is simply reregistered at a new location. Of course, instead of just clobbering the destination range, it would be very easy (easier even) to insert the range at another location.
But... both source and destination ranges will still have to be checked, as we may have moved cells that were part of a range calculation, or which now enter a range calculation.
- Deleting a square range.
To delete a square range in the grid, one might think it would be enough to just blank the values of every cell in a range: naively, this would be equivalent to the simple update above (1), but it's preferable to also delete references to the cells being deleted, so actually this is the same as the 'clobbering' section of Moving ranges (3).
I'm not planning to support the "shift cells left" or up behaviour offered by, for example, Microsoft Excel. It's occasionally useful, but I'm not convinced it's worth the implementation bother.
- Deleting a range of Rows/Columns.
However, deletion of rows and columns will be supported almost as simply as just removing the required range of Rows/Columns. Note that in this case we don't clobber every range that intersects the Deleted range.
- If we've deleted a range in the middle of an existing range, then we need take no action (beyond scheduling that range for update in the dependency graph).
- If we've deleted a range that overlaps the edges of an existing range then we could shift the edge of the range to the next remaining row/column. For example, if we delete column B, then a range like B5:E7 might change to become C5:E7 instead. It would obviously also be scheduled for update.
- If however we've deleted a range that completely surrounds the existing range, then that range will be deleted and scheduled to be clobbered.
- Inserting a square range of cells.
e.g., and shifting the cells at the destination right or down. This will not be supported. Because
- Can be confusing and cause cells to become out of synch with cells in other rows.
- Would be more bother to implement than it's worth.
- Inserting rows/columns.
Interestingly enough, this could be done simply by inserting the row or column into the Grid, and renumbering. The references of cells after the insertion will have changed Address, but this can be lazily calculated as needed.
This simple implementation is only assured if I don't have any formulas that count on the layout rather than the existing cell values. I'm assuming that things like SUM, AVERAGE etc. will only operate on cells with values. This means that inserting blank rows into a range would have absolutely no effect.
If, however, I have any formula that either
- Operates on blank cells (putative COUNT_BLANKS, AVERAGE_INC_BLANKS functions)
- Translates into the address of the range (ADDRESS)
Cell evaluation: yet more thoughts
I'm getting dangerously near to writing some code... ;-> but I keep finding myself coming back to the design of the evaluation model.I've been in contact with Michael Zemljanukha, the author of Microcalc, which has been very interesting: I'll write more about it soon. But for now I wanted to comment on an issue Michael mentioned with the current version of Microcalc:
The main problem of existing algorithm is that it doesn't support "massive" updates, when there are many cells changed as it may happen when you insert a row/column (the most possible case) or copying a range of cells.This is clearly something to think about which I've been avoiding: the impact of updating or moving a range of cells and, a related issue, updating a single cell which happens to be inside a range which is referred to by a formula.
| A | B | |
|---|---|---|
| 1 | 100 | 200 <<< |
| 2 | 300 | 400 |
| 3 | 500 | 600 |
| 4 | ||
| 5 | =B2 * 4 | =SUM(A1:B3) |
In this table, when we change the cell B2, two cells have to change:
- not only A5 (which refers to B2 explicitly)
- but also B5 (which refers to the range A1:A3 that contains B2)
Though this could work, it is inefficient on a number of counts:
- Every cell needs to reference every range that contains it. (Storage)
- If I create a formula that references a range =sum(A1:E500), I now have to iterate over several thousand cells, adding a reference to the new containing range, even before calculating. (Too much like hard work)
- Completely inside the changed range. Any formula that refers to the range will have to be recalculated.
- Completely outside the cha"http://www.symbiandiaries.com/archives/osfameron/eval_3.png"nged range. Not affected.
- Overlapping: the range will need to be recalculated exactly as per 1.
- The Grid will need to maintain a collection of Range objects.
- Range objects will have a method .intersect(Range r)
which will either
- return the intersection of 2 ranges
- return null if there is no intersection
- Every time a range of cells is updated, it will be compared against every Range stored by the Grid. If the 2 have an intersection then the Range will be added to the dependency graph.
- As the range being updated could be a single cell, we could handle this by creating a range consisting of just that cell to compare with. But I think it may be more elegant to have the Cell class implement an interface AbstractRange shared with Range objects?
- As we do the BFS walk of the dependency-graph, every time we visit a new node, we need to check which Ranges it is in. This will also need to be checked for circularity.
- Start with a graph node Root
- Add an edge from Root to every cell in the updated range.
- Add an edge from Root to any ranges intersecting with the updated range.
- Create a HashTable that also contains these items, to show that they have already been "seen".
- Start the BFS iteration. For every new (e.g. "unseen") node that is visited (be it a Range or a Cell) check for overlapping Ranges. If there are any, then create an edge first to a Temporary node, and then add edges from the Temporary node to these Ranges.
The reason for creating a temporary node is that Range dependencies of a Cell or a Range may change, and it's easier to create a single disposable node to store them in briefly. (I suppose that this node could be cached and only recalculated when necessary?)
Though I don't know if it's that important for Gilgamesh to support volatile functions (like TIME and RANDOM, which change every time the sheet is recalculated), all we have to do is to create a node called Volatile which contains edges to any cell that contains a volatile function.
Putting this all together, we get something like:
units
Came across Mark Jason Dominus's program units, which converts intelligently between human-specified scales. (To compare to Frink)Cell evaluation order
I've given this some thought and I'd been planning to get to this shortly, but Alan Eliasen asked about it. Alan gave a good link to Bob Frankston's notes on the development of VisiCalc which also mentioned the evaluation strategy they used:
Row order
Every time a cell is changed, loop through all the other cells updating them once. (An obvious alternative strategy is column order).
I'd heard of this, considered it briefly, and rejected it because this brute force sounded inelegant, involving too much unnecessary work, especially for a larger sheet.
Cascading updates
Originally, I'd planned for every cell to keep a list of pointers to dependent cells (any cell that references it).
When a cell is updated it will ask its dependent cells to update themselves. Those cells in turn may update other dependent cells: this means that there is a risk of circular referencing. So when I trigger the update I pass a reference to a Collection (an ArrayList, Vector, or HashTable) adding the original cell..-->B--. / \ A +-->D-->E \ / `-->C--'
Of course, the same cell may need to update itself 2 or more times: this is OK, as long as each time is on a different evaluation path. Here, D is evaluated twice, but the cell-paths passed in are not circular:
Each subsequent cell checks if it is in that Collection before appending itself to it. If it's already there, then this calculation path was circular, and should generate an error. Here, cell C is asked to recalculate in a path that already includes C:(A) .-->B--.(AB) / \ (ABD) A +-->D------>E \ / (ACD) `-->C--'(AC) (A)
(A)
.-->B--.(AB)
/ \ (ABD)
A +-->D------>E
\ / (ACD) |
`-->C--'(AC) |
(A) ^ /
| /
`------------'
(ACDE)
^
Circularity
Error here!
Natural order
This would work, but means that the same cell may have to recalculate more than once, which could be inefficient, and might have some pathological cases.
It would be best to calculate in which order the cells have to be updated, and then calculate them all once only. This is called 'natural order'. And while you might think that calculating the order to evaluate cells in was a tricky task, in fact there is a simple way to do it.
If you have a Computer Science background, you might recognize the dependency diagrams above as a DAG, or Directed Acyclic Graph. And you might realize that all we have to do get the evaluation order is to run a topological sort on single-source DAG. If you don't understand that, then read on!
Graphs in computer science aren't the same as the nice bar-charts and diagrams that non-geeks might expect them to be. They are just
- a collection of nodes (like our Cells)
- connected by edges to other nodes. (the references to other cells)
- The connections can be directed, which means they go in one direction only (Cell A1 is a dependency of B5. But not the other way round!)
- The graph can be acyclic if there are no paths which come back on themselves (e.g. there are no circular references).
- A graph can have one or more sources, which is the entry point into the graph. (In the diagram above, I showed a graph with a source at Cell A. But of course if we were updating Cell B, C, D... Z, we would use the part of the graph that started with that cell. That sub-graph might not go to every node in the full graph).
Topological sort is a sorting technique that involves visiting each node and the nodes it links to in turn (often called 'traversing' the graph) in such a way that all dependent nodes are listed last. You can walk the graph in 2 ways, "Breadth first" (BFS), or "Depth first" (DFS). This is actually rather intuitive:
- Breadth-first means visiting all the nodes from the Source node. Then all the nodes pointed to from all of these nodes. And so on.
- Depth-first means starting with the Source node, and diving all the way down first one branch, then the next.
Starting with cell A we follow this branch to its end (depth first).-->B--. / \ A +-->D-->E \ / `-->C--'
- A
- A B
- A B D
- A B D E
- A B D E
- A B D E C
- A B
DE C D (now that D has appeared later, we scrap the earlier entry) - A B
D EC D E
- A B C D E
Beginning an implementation
It is fairly trivial to implement a minimal graph-walking algorithm doing a simple recursive tree walk. Of course it's often more elegant to do this iteratively. (For example Dominus will have some chapters on this in his forthcoming book). Using the Iterator interface is also Java best practise. (Though I think J2ME doesn't define the Iterator interface).
Here's some basic setup for a basic Node class.:
import java.util.*;
public class Node {
private Vector edges;
private String name;
public Node(String name) {
edges = new Vector();
this.name = name;
}
public Collection edges() {
return edges;
}
public String toString() {
return name;
}
}
It is fairly easy to add a DFS Iterator class:
import java.util.*;
public class DFS implements Iterator {
private Vector iterators;
private Node curr_node;
private Iterator curr_it;
public DFS(Node source) {
curr_node = source;
curr_it = curr_node.edges().iterator();
iterators = new Vector();
iterators.addElement(curr_it);
}
/** The class works by keeping a stack of Iterators
* for each fork in the Graph. The hasNext() method
* checks if any of the Iterators in the stack have
* any more Nodes to return (e.g. if they return true
* on hasNext()).
*/
public boolean hasNext() {
while (! iterators.isEmpty()) {
curr_it = (Iterator) iterators.lastElement();
if (curr_it.hasNext()) {
return true;
}
iterators.remove(iterators.lastElement());
}
return false;
}
/** Every time a new object is selected, add the
* Iterator for its own edges to the stack.
*/
public Object next() {
Node next = (Node) curr_it.next();
Iterator new_it = next.edges().iterator();
iterators.addElement(new_it);
curr_it = new_it;
return next;
}
public void remove() {
; // just to fulfil requirements of interace.
}
}
(Adding checking for cyclic paths in the graph is left
as an exercise to the reader...)
And of course, add a method to the Node class:
public Iterator DFSIterator() {
return new DFS(this);
}
Now it's easy to create the Topologically sorted dependency list
(add this method to Node class).
Iterate through the Graph, adding the latest node to the end, first of all
removing any previous occurrences:
public Vector dependencyList() {
Vector v = new Vector();
v.add(this);
Iterator it = this.DFSIterator();
while (it.hasNext()) {
Object o = it.next();
if (v.contains(o)) {
v.remove(o);
}
v.add(o);
}
return v;
}
Coming up soon:
- Maybe I'm wrong about optimization of row-based vs natural?
- Why we might want Circularity
Pluggable Evaluation Engines
After some further thought, it seems clear that the Evaluation Engine itself should be loosely coupled from the Spreadsheet Container Model, that is to say, Grid, Row, Column, & Cell structure, and from things like Evaluation order processing (to be blogged shortly).
I'm not sure if I've thought about, and indeed written this up, as coherently as previous entries: comments and discussion welcome...
The Grid will maintain the containers (Rows & Columns), which in turn maintain Cells. Cells contain a Value and a Formula. The Formula is turned into a Value by the Evaluation engine. This means that the representation and the semantics of Values are limited by the Evaluation engine. So are the Data Type inferencing rules. For example:- If I were to use Frink as an Evaluation engine, then the Values used by the
spreadsheet might be
- 5 metres
- 1 jeroboam
- 40 acres
Frink-based calculations would track units across calculations so A1 * A2 where A1 and A2 were metre lengths would give a result in square-metres. Multiplying a length by a voltage might give a semantic error.
- The simple evaluation engine that I was planning would contain some basic
data types like
- 10.4 (number - Fixed Point)
- 20 (number - Integer)
- 20% (number - Percentage)
- $20.00 (number - Currency)
- 4/5 (date - 4th of May. Not 0.8!)
- The quick brown fox (string)
- Other evaluation engines (such as Simkin and others) may have other semantics and representations which allow and limit them to certain types of calculations and evaluations.
Effectively, there will be a simple interface that an Evaluation engine will have to follow:
- A Cell may be asked to recalculate itself.
- A formula may be asked to return its String representation. (As a formula will very likely have references to Cells and Cell ranges, the formula would also be expected to display the current address or name of those ranges) e.g. A5 + A6 or quarterly_sales_results_total * 4
- A value may be asked to return its String representation.
- A formula may be asked to return a Collection of dependencies after it has been parsed. (The evaluation engine will use this in calculating the evaluation order of cells).
- The Data model will never want to be passed an actual Value (in fact, it couldn't know what to do with one if it got it!), only the String representation of it.
I think that the User Interface will be more tightly coupled to the evaluation engine. For example:
- Formats may be available which filter the value. For example, a
Value representing 3.141592 might be shown as:
- 3.141592
- 3.142
- 3
- 3.14%
- $3.14
- 03.14
- 22/7
- PI
- If the Value is a Date, I may be able to tap on a DNL (Direct Navigational Link) which brings up a Calendar chooser for me to replace with another date.
Hmmm, I wonder if all this means is that the Expression evaluator must conform to an interface which allows the UI to query it about the type of Value of a given cell, and to request it to format the result in an appropriate way?
Loose-coupling between UI and Data Evaluation would have some benefits, but I wonder if it as clear cut as keeping the Container model separate?
Expression evaluation: Simkin, Micromath, Frink
I've come across some other projects, and had to re-question whether Gilgamesh will have its own expression evaluator as I suggested above. All comments welcome!
Simkin
At the pub-meet I met Simon Whiteside, enthusiastically promoting his Open Sourced scripting language, Simkin. I'd read the blurb on it before, and thought "huh?" before bookmarking it and moving on. Simon says that Simkin sometimes gets this reaction, but has convinced me that it's worth looking at in more detail!
It's lightweight (50K jarfile), is implemented in both C++ and Java, and has been ported to J2ME.
it is also an expression evaluator which, if I understand rightly, can easily be customized to include custom objects. So, for the purpose of Gilgamesh, something like
=A5 * 4 + sum(B2:C5)Could actually get parsed as a Simkin expression which refers to Gilgamesh objects for the Cell (A5) and Range (B2:C5).
Though I'm happy to steal, um, leverage existing code to parse formulas (as I wrote above, I was quite happy to leave this to someone else!), I guess that it will have some impact on Data representation, and on formatting of Cell results. (I'll try to write up my initial thoughts on these soon). So I have to look into any existing code and API before I commit. Some good documentation from the Simkin site itself, including links to off-site articles.
If I do use Simkin, I should also think about using it as an on-board extension language!: I hadn't thought about having an scripting language in Gilgamesh, because it seems like unnecessary bloat, but if I get it for free it's worth thinking about.
Micromath
Some time ago, I looked at the Micromath library, which powers Microcalc. Microcalc is one of the big influences on this project, in terms of inspiration, and a benchmark to try to compete with. Rafe has suggested it'd be worth getting in touch with the Microcalc development team (Michael Zemljanukha) to discuss the two projects: now on my todo list!
J2ME doesn't support Floating Point maths. Micromath gives Fixed Decimal maths support, and is a very compact Java library. However I'm leaning towards using the MathFP library (mainly because it has better documentation.)
Frink
Alan Eliasen has posted a comment mentioning his project Frink. From a first quick read of the (nicely detailed) docs, you could describe it as a mix between an expression evaluator that knows about the world, a miscellany of facts and figures, and a programming language that, like Perl, tries to DWIM ('Do What I Mean') in some really clever ways.
In one of the wonderfully whimsical examples in the docs, he calculating the rainfall in the Biblical Great Flood using the formula:
depth = 29030 feet + 15 biblicalcubits - (2.4 inches/ year 4000 years)Frink knows about feet, and inches, and years, and um... biblical cubits. Not to mention currencies, current and historical!
It also tracks the unit type of a calculation, making sure that you do sensible things with them: e.g. you can add 1 mile + 4 metres but it wouldn't make sense to add 1 mile + 4 volts. (2 metres) * (2 metres) will actually know to return an area in square metres! I love this idea: surely this should be mainstream?
Alan noted that he'd thought about using this in a Spreadsheet: I would love to see that happen, and I have to admit I'd be seriously tempted to use it in Gilgamesh. On the minus side:
- Apparently it can be a little heavyweight: the data file is already large, and when it is (very cleverly) parsed to get all the relationships between the different data types, the resulting data structure is quite complex. Update: See Alan's comment for some clarification.
- Though it's been ported to constrained devices, including my target platform, the SonyEricsson P800, it's been ported to PersonalJava rather than MIDP (see above).
- I don't think it's designed to be plugged in to object models, worth investigating though.
- It isn't open source. See the FAQ for a reasonable reason why not.
Formulas
I hinted in the entry on the Grid that each cell would contain a list of cells that it refers to in formulas.
A
+------+
1| 1 |
+------+
2|A1*2 | <-- references: A1
+------+
3|A1+A2 | <-- references: A1,A2
+------+
- Functions
- Cell references
- Constant data (numbers, strings, dates)
Some examples
(Don't pay too much attention to the pseudo-syntax)
A1+A2
- function(+)
- ref(A1)
- ref(A2)
if(A1==23 then "Yes" else "No)
- function(if)
- function(equals)
- ref(a1)
- constant(23)
- constant("Yes")
- constant("No")
As you can see, this is much more easily translated into the parse-tree above.if(equals(A1, 23), "Yes", "No") // Excel syntax
S-expressions
The easiest (for the implementer) way of having formulas easily parseable would be to use the Lisp syntax of S-expressions. 99% of Lisp commands are written like thisIt looks a bit odd if you're not used to it, but it's trivial to build the parser. My first design idea is this:(function arg1 arg2 arg3 ...) Converting the formulae above: (+ A1 A2) (if (equals A1 A2) "Yes" "No")
- If you write a formula beginning with parenthesis "(", then it will be parsed as an S-expression.
- If you write a formula beginning with an equals "=", just like Excel and co,
then it will be parsed more cleverly.
=1 + 2 // arithmetic operators come inline =function(arg, arg) // functions as standard =A1 // reference unchanged
- The S-expression parsing will get implemented first: we can worry about the syntactic sugar later
- Reference to a Function object
- Zero or more argmuents
(if (= A1, 23), "Yes", "No)
- Formula:
- Function: if
- Formula------------.
- Constant: "Yes" \
- Constant: "No" \
- Function: =
- Reference: A1
- Constant: 23
public abstract class Function {
public String display;
public boolean CheckArgs(Value[] args) {
// ... (filled in by subclass)
}
public Value execute(Value[] args) {
// ... (filled in by subclass)
}
}
public class EqualsFunction extends Function {
public EqualsFunction() {
display = "=";
}
public boolean CheckArgs(Value[] args) {
if (args.size == 2) {
return true;
} else {
return false;
}
}
public Value execute(Value[] args) {
if args[0].equals(args[1]) {
return BooleanValue.TRUE;
} else {
return BooleanValue.FALSE;
}
}
}
Common framework for data
NB: I'm assuming that all the possible data-types (Booleans, Formulas, Arguments, Strings, Cell References) inherit from a parent class (here Value). That's because we need to be able to pass them around, store them, and use them consistently.This might well be too heavyweight for being on a J2ME constrained device. But I think it will have its advantages: we'll see as we go on and try to optimize later if we need to. More on this topic later.
Designing the Grid
One of the most important data-structures to determine for a spreadsheet application has to be the Grid. It's what gives us the concepts of "Rows" and "Columns" of cells, and gives us a nice way of formatting related items like records of data into tables.
2-d array
The naïve way of implementing this (and I mean the way that I first thought of ;->) is to use a 2-dimensional array. That is to say, if the grid is 30 x 30 we'd have a grid something like:1 2 3 4 5 ..30 +-+-+-+-+-+--- 1| | | | | | +-+-+-+-+-+--- 2| | | | | | +-+-+-+-+-+--- 3| | | | | | +-+-+-+-+-+--- 4| | | | | | :+-+-+-+-+-+--- :| | | | | | 30 : : : : :
Array of arrays
Of course, in some languages, such as Java and Perl, this is implemented internally as an array of arrays. Though it's declared and used as if it was really a grid, in fact each individual array can contain a different number of elements.Already, this seems to have some advantages, in that some rows may have more data than others. We don't have to store cells that don't exist (i.e. it's a sparse data-structure). Once we start thinking about rows of data, this leads to some other considerations:+-+ +-+-+ |1|->| | | +-+ +-+-+ |2|->| | +-+ +-+-+-+-+ |3|->| | | | | +-+ +-+-+-+-+ |4|->| | | +-+ +-+-+-+-+-+ |5|->| | | | | | +-+ +-+-+-+-+-+ |6|->| | | +-+ +-+-+ : : :
- Add more rows to the end of the grid
- Delete a row
- Insert a row in the middle of the grid
Cell references
Most of the power of spreadsheets comes from the fact that cells can reference other cells:If we add a rowA B C +---+---+-----+ 1| | |A2+B2| +---+---+-----+ 2| 3| 5| | +---+---+-----+
I'd expect the reference in cell C1 to now point to A3+B3. Hopefully there is a more elegant way for us to do this than to go through every cell in the grid updating the formulas.A B C +---+---+-----+ 1| | |A2+B2| <-- +---+---+-----+ 2| | | | +---+---+-----+ 3| 3| 5| | +---+---+-----+
References to cells, not to addresses
The formulas shouldn't contain references to a particular address, but to the Object of the cell. (I'm assuming basic familiarity with OO, especially Java here).
public class Cell {
/** Cell has an Array of other Cell objects which it refers to */
Cell[] references;
}
Cells know which row and column they're in
The best way for the cell to know its own address is to keep a reference to which row and column it's in. The row and column will know which number they are.
+-+-+-+-+-+-+-+ B
1| | |X| | | | | +-+
+-+-+-+-+-+-+-+ | |
^ +-+
/ |X|
/ ->+-+
+-+ / | |
|X|------------ +-+
+-+
public class Cell {
Line row;
Line col;
Cell[] references;
}
If the Cell object needs to know its address, it can query the Row and the Column. All that needs to happen when Rows or Columns are inserted or moved is for them to be renumbered. This implies that the Grid contains
- A list of rows
- A list of columns
Deleting a line
Of course there is some additional complexity here:A B C +---+---+---+ 1| | |=A2| +---+---+---+ 2| 33| 12| |<-- delete this line +---+---+---+
- Delete Row 2
- For each cell in the row, delete the cell from the relevant column
- 33 (delete from column A)
- 12 (delete from column B)
A B C +---+---+---+ 1| | |=##|<-- error! +---+---+---+
Generic deletion of a line
(e.g. row OR column)- Delete the line
- (renumber the list of lines)
- For each cell in the line
- delete the cell from the relevant perpendicular line.
- Notify any dependent cells that this cell has now been deleted.